Tüm Makine Öğrenmesi Modellerinin Açıklaması

Makine öğrenmesi modelleri denetimli ve denetimsiz olarak kategorize edilir. Denetimli bir modelse regresyon veya sınıflandırma modeli olarak alt kategorilere ayrılır.
BİLİNMESİ GEREKEN 9 MAKİNE ÖĞRENMESİ MODELİ
- Doğrusal Regresyon
- Karar ağacı
- Rastgele orman
- Sinir ağı
- Lojistik regresyon
- Destek vektör makinesi
- Naif bayanlar
- Kümeleme
- Temel bileşenler Analizi
Bu terimlerin ne anlama geldiğini ve her kategoriye giren karşılık gelen modelleri gözden geçireceğiz.
Denetimli Makine Öğrenmesi Modellerinin Açıklaması
Denetimli öğrenme, örnek girdi-çıktı çiftlerine dayalı olarak bir girdiyi bir çıktıyla eşleştiren bir fonksiyonun öğrenilmesini içerir.
Örneğin, yaş (girdi) ve boy (çıktı) olmak üzere iki değişkenli bir veri setim olsaydı, bir kişinin boyunu yaşına göre tahmin etmek için denetimli bir öğrenme modeli uygulayabilirdim.
Denetimli öğrenmede iki alt kategori vardır: regresyon ve sınıflandırma.
Makine Öğrenmesi için Regresyon Modelleri
Regresyon modellerinde çıktı süreklidir. Aşağıda en yaygın regresyon modeli türlerinden bazıları verilmiştir.
DOĞRUSAL REGRESYON

Doğrusal regresyonun amacı verilere en iyi uyan doğruyu bulmaktır. Doğrusal regresyonun uzantıları, çoklu doğrusal regresyonu veya en uygun düzlemin bulunmasını ve polinom regresyonunu veya en iyi uyum eğrisinin bulunmasını içerir.
KARAR AĞACI
Karar ağaçları yöneylem araştırmasında, stratejik planlamada ve makine öğrenmesinde kullanılan popüler bir modeldir. Karar ağacındaki her kareye düğüm adı verilir ve ne kadar çok düğüme sahipseniz karar ağacınız genellikle o kadar doğru olur. Karar ağacının kararın verildiği son düğümlerine ağacın yaprakları denir. Karar ağaçları sezgiseldir ve oluşturulması kolaydır ancak doğruluk söz konusu olduğunda yetersiz kalır.
RASTGELE ORMAN
Rastgele ormanlar, karar ağaçlarından yola çıkanbir topluluk öğrenme tekniğidir. Rastgele ormanlar, orijinal verilerin önyüklemeli veri kümelerini kullanarak birden fazla karar ağacı oluşturmayı ve karar ağacının her adımında değişkenlerin bir alt kümesini rastgele seçmeyi içerir. Model daha sonra her karar ağacının tüm tahminlerinin modunu seçer. Bunun amacı nedir? “Çoğunluk kazanır” modeline güvenerek tek bir ağaçtan kaynaklanan hata riskini azaltır.

Örneğin, eğer bir karar ağacı (üçüncüsü) oluşturursak, 0’ı tahmin eder. Ancak dört karar ağacının hepsinin moduna güvenirsek tahmin edilen değer 1 olur. Bu, rastgele ormanların gücüdür.
SİNİR AĞI
Sinir ağları, matematiksel denklemlerden oluşan birer modeldir. Bu modeller, bir veya daha fazla girdi değişkeni alır ve bir denklem ağından geçirerek bir veya daha fazla çıktı değişkeni elde eder. Sinir ağları, bir girdi vektörü aldığını ve bir çıktı vektörü döndürdüğünü de söyleyebiliriz.
Sinir ağları, katmanlar halinde düzenlenmiş düğümlerden oluşur. Giriş katmanı, girdi değişkenlerini alır. Gizli katmanlar, girdileri işleyen ve çıktıları üreten düğümlerden oluşur. Çıktı katmanı, çıktı değişkenlerini üretir.
Gizli katmanlardaki her düğüm, hem doğrusal bir fonksiyonu hem de bir aktivasyon fonksiyonunu temsil eder. Doğrusal fonksiyon, düğüme gelen girdileri birleştirir. Aktivasyon fonksiyonu ise, düğümün çıktısını belirler.
Makine Öğrenmesi Sınıflandırma Modelleri
Sınıflandırma modellerinde çıktı ayrıktır. Aşağıda en yaygın sınıflandırma modeli türlerinden bazıları verilmiştir.
LOJİSTİK REGRESYON
Lojistik regresyon, iki veya daha fazla sonucun olasılığını tahmin etmek için kullanılan bir istatistiksel modelleme tekniğidir. Doğrusal regresyona benzer, ancak doğrusal regresyonun aksine, lojistik regresyonun çıktıları yalnızca 0 ile 1 arasında olabilir.
Lojistik regresyon, bir sigmoid fonksiyonunu kullanarak tahmin edilen olasılıkları elde eder. Sigmoid fonksiyonu, giriş değerinin büyüklüğüne bağlı olarak çıktıyı 0 ile 1 arasında bir değere dönüştürür.
Lojistik regresyon, çeşitli uygulamalarda kullanılabilir. Örneğin, bir müşterinin bir ürün satın alma olasılığını tahmin etmek için, bir hastanın bir hastalığı geliştirme olasılığını tahmin etmek için veya bir kredi başvurucusunun kredi geri ödeme olasılığını tahmin etmek için kullanılabilir.
DESTEK VEKTÖR MAKİNESİ
Destek vektör makinesi , aslında oldukça karmaşık olabilen ancak en temel düzeyde oldukça sezgisel olan denetimli bir sınıflandırma tekniğidir.
İki veri sınıfının olduğunu varsayalım. Bir destek vektör makinesi, iki veri sınıfı arasında, iki sınıf arasındaki marjı maksimuma çıkaran bir hiperdüzlem veya sınır bulacaktır. İki sınıfı ayırabilecek birçok düzlem vardır, ancak yalnızca bir düzlem sınıflar arasındaki marjı veya mesafeyi maksimuma çıkarabilir.
NAIVE BAYES
Naive Bayes, veri biliminde kullanılan bir başka popüler sınıflandırıcıdır. Bunun arkasındaki fikir Bayes Teoremi tarafından yönlendirilmektedir:
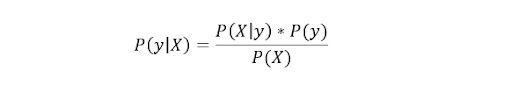
Bu denklem şu soruyu cevaplamak için kullanılır: “X verildiğinde y’nin (çıkış değişkenimin) olasılığı nedir?” Ve değişkenlerin sınıftan bağımsız olduğuna dair saf varsayımdan dolayı şunu söyleyebilirsiniz:

Paydayı çıkararak P(y|X)’in sağ tarafla orantılı olduğunu söyleyebiliriz.

Bu nedenle amaç, maksimum orantılı olasılığa sahip y sınıfını bulmaktır.
KARAR AĞACI, RASTGELE ORMAN, SİNİR AĞI
Bu modeller daha önce açıklandığı gibi aynı mantığı takip etmektedir. Tek fark, çıktının sürekli değil ayrık olmasıdır.
Denetimsiz Öğrenme Makine Öğrenmesi Modelleri
Denetimli öğrenmenin aksine, denetimsiz öğrenme, etiketli sonuçlara referans olmadan girdi verilerinden çıkarımlar yapmak ve modeller bulmak için kullanılır. Denetimsiz öğrenmede kullanılan iki ana yöntem, kümeleme ve boyutluluğun azaltılmasıdır.
KÜMELEME
Kümeleme, veri noktalarının gruplandırılmasını veya kümelenmesini içeren denetimsiz bir tekniktir. Müşteri segmentasyonu, dolandırıcılık tespiti ve belge sınıflandırması için sıklıkla kullanılır.
Yaygın kümeleme teknikleri arasında k-ortalamalı kümeleme, hiyerarşik kümeleme, ortalama kaydırmalı kümeleme ve yoğunluğa dayalı kümeleme yer alır. Her tekniğin küme bulma konusunda farklı bir yöntemi olsa da hepsi aynı şeyi başarmayı amaçlamaktadır.
Boyutsal küçülme
Boyut azaltma, bir dizi temel değişken elde ederek, söz konusu rastgele değişkenlerin sayısını azaltma işlemidir. Daha basit bir ifadeyle, özellik kümenizin boyutunun küçültülmesi, yani özelliklerin sayısının azaltılması işlemidir. Boyut azaltma tekniklerinin çoğu, özellik eleme veya özellik çıkarma olarak kategorize edilebilir .
Boyutsallığı azaltmanın popüler bir yöntemine temel bileşen analizi denir.
TEMEL BİLEŞEN ANALİZİ (PCA)
En basit anlamıyla PCA, üç boyut gibi daha yüksek boyutlu verilerin iki boyut gibi daha küçük bir alana yansıtılmasını içerir. Bu, tüm orijinal değişkenleri modelde tutarken, verilerin daha düşük bir boyutuna (üç yerine iki boyut) neden olur.



