Optik Karakter Tanıma (OCR) - 2023 Kılavuzu
- OCR nedir ve nasıl çalışır?
- OCR için en iyi araçlar, algoritmalar ve teknikler.
- OCR kullanmanın faydaları
- Kullanım örnekleri ve OCR uygulamaları

Görsel Metin Tanıma
Optik Karakter Tanıma, yapay zeka, örüntü tanıma ve bilgisayar görüşünde önemli bir araştırma alanıdır . OCR aynı zamanda yapay teknoloji araştırmalarının en eski alanlarından biriydi ve olgun bir teknoloji olarak ortaya çıktı.
OCR, 1913 yılında Dr. Edmund Fournier d’Albe’nin görme engelli insanlar için metni tarayıp sese dönüştürmek için Optophone’u icat etmesiyle başladı. O zamandan beri, OCR teknolojisi birden çok geliştirme aşamasından geçti.
1990’larda tarihi gazetelerin dijitalleşmesi ile teknoloji ön plana çıktı. Ayrıca akıllı telefonların ve elektronik belgelerin ortaya çıkması da OCR teknolojisinde daha fazla ilerlemeye yol açmaktadır.

Optik Karakter Tanıma (OCR) nedir?
OCR, Optik Karakter Tanıma anlamına gelir ve bir görüntü dosyası veya taranmış bir belge gibi fiziksel bir belge içindeki metni (yazılı veya basılı) elektronik olarak tanımlayan ve bunu veriler için kullanılmak üzere makine tarafından okunabilen bir metin formuna dönüştüren bir yazılım teknolojisine atıfta bulunur. işleme. Metin tanıma olarak da bilinir.
Kısacası, optik karakter tanıma yazılımı, görüntüleri veya fiziksel belgeleri aranabilir bir forma dönüştürmeye yardımcı olur. OCR örnekleri, metin çıkarma araçları, PDF’den .txt’ye dönüştürücüler ve Google’ın resim arama işlevidir.

Sahne Metni Tanıma (STR) nedir?
Bilgisayarla görmede, makineler önce metin bölgelerini algılayarak, bu bölgeleri kırparak ve ardından bu bölgelerdeki metni tanıyarak doğal sahnelerdeki metni okuyabilir. Kırpılan bölgelerdeki metni tanımaya yönelik görsel görev, Sahne Metni Tanıma (STR) olarak adlandırılır.
STR, yol işaretlerini, reklam panolarını, logoları ve gömleklerdeki metinler, kağıt faturalar vb. basılı nesneleri okumayı mümkün kılar. STR uygulamaları sürücüsüz arabalar, artırılmış gerçeklik, perakende satış analizi, eğitim, görme engelliler vb.
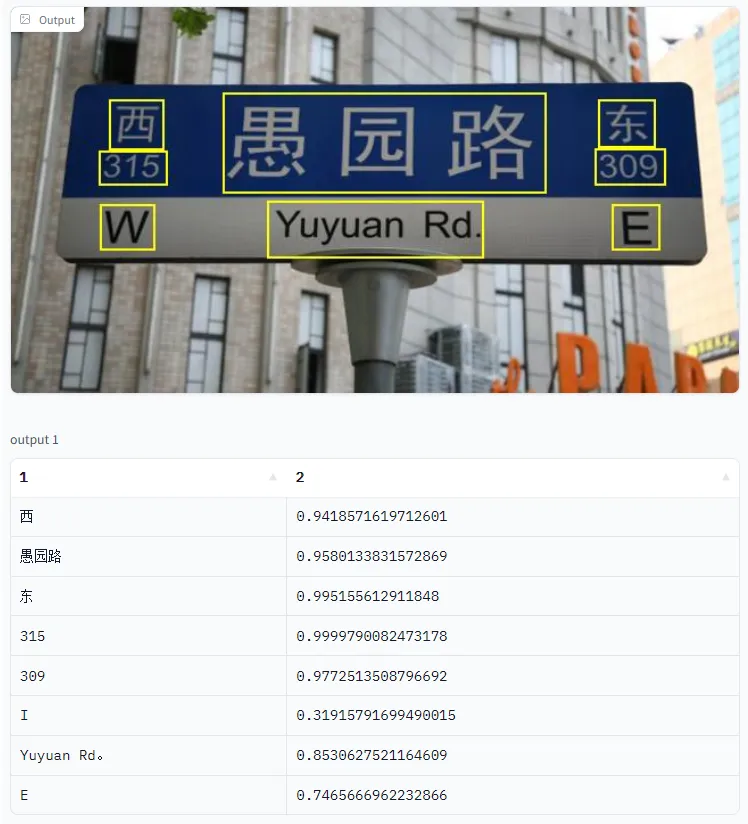
OCR ve STR arasındaki fark nedir?
OCR ile STR karşılaştırıldığında, optik karakter tanıma (OCR), metin niteliklerinin tek tip bir giriş formunda sağlandığı yerlerde uygulanabilir. Dolayısıyla STR, değişen yazı tipi stilleri, metin şekilleri, aydınlatma, yönlendirme, kapatma (kısmen gizli metin) ve tutarsız kamera koşullarına sahip metinleri okuyabilir.
Genel olarak, sahne metni tanıma, gürültülü, bulanık veya bozuk giriş görüntülerine sahip çok zorlu, doğal ortamları içeren gerçek dünya senaryolarında Yapay Zeka algoritmalarıyla Metin okumak için gereklidir.
Optik Karakter Tanıma nasıl çalışır?
OCR kavramı basittir. Bununla birlikte, yazı tipi çeşitliliği veya harf oluşumu için kullanılan yöntemler gibi çeşitli faktörler nedeniyle uygulanması oldukça zor olabilir. Örneğin, bir OCR uygulaması, girdi olarak daktilo edilmiş yazı yerine dijital olmayan el yazısı örnekleri kullanıldığında katlanarak daha karmaşık hale gelebilir.
Tüm OCR süreci, temel olarak üç hedefi içeren bir dizi adımı içerir: görüntünün ön işlenmesi, karakter tanıma ve belirli çıktının son işlenmesi. OCR’nin aşağı akış görevleri arasında, metin ve konuşmanın anlamını yalnızca okumak değil aynı zamanda analiz etmek ve anlamak için Doğal Dil İşleme (NLP) yer alır.
Test için OCR demo yazılımı
OCR yazılımını çalışırken görmek için, kullanmayı deneyebileceğiniz basit bir web demo yazılımı bulduk: Brandfolder’dan Text Extractor Tool . Bu optik karakter tanıma çevrimiçi aracı, bir metin görüntüsünü (ekran görüntüsü gibi) düz metne dönüştürebilir. Kişisel tanımlayıcı bilgiler içeren hassas resimler veya fotoğraflar yüklemekten kaçındığınızdan emin olun.
Daha kapsamlı bir OCR demosu için, birden çok dilde tüm cihazlarda rahatça çalışan Çok Dilde OCR’ye izin veren Optik Karakter Tanıma algoritması demosuna bu görüntüyü keşfedin.

OCR Süreci
Aşağıda, optik karakter tanımanın nasıl çalıştığını göstereceğiz ve geleneksel OCR teknolojilerinin ana adımlarını açıklayacağız.
1. Belgeyi Tarama
Bu, belgeyi taramak için bir tarayıcıya bağlanan OCR’nin ana adımıdır. Belgeyi taramak, girişleri standartlaştırdığından, OCR yazılımı oluşturulurken dikkate alınması gereken değişken sayısını azaltır. Ayrıca bu adım, belirli belgenin mükemmel şekilde hizalanmasını ve boyutlandırılmasını sağlayarak tüm sürecin verimliliğini özellikle artırır. Bu ilk adım , sonraki görüntü işleme görevlerini belirli görüntü alanlarına odaklamak için nesne algılamayı da içerebilir .
2. Görüntüyü İyileştirme
Bu adımda, optik karakter tanıma yazılımı, belgenin yakalanması gereken öğelerini geliştirir. Toz parçacıkları gibi tüm kusurlar ortadan kaldırılır ve düz ve net bir metin elde etmek için kenarlar ve pikseller yumuşatılır.
Bu adım, programın, örneğin lekeler veya düzensiz karanlık alanlar olmadan girilen kelimeleri net bir şekilde “görebilmesini” sağlarken verileri yakalamasını kolaylaştırır. Bu tür görüntü işleme görevleri, görüntüleri keskinleştirmek veya otomatik olarak parlaklaştırmak için her türlü görüntü hattında gereklidir. OpenCV, genellikle bu tür görevler için kullanılan bir araç seti sağlar.
3. Binarlaştırma
İyileştirilmiş görüntü belgesi daha sonra, yalnızca siyah ve beyaz renkleri içeren, siyah veya koyu alanların karakter olarak tanımlandığı iki düzeyli bir belge görüntüsüne dönüştürülür. Aynı zamanda beyaz veya açık renkli alanlar arka plan olarak tanımlanır.
Bu adım , karakterlerin en iyi şekilde tanınmasını sağlayan ön plan metnini arka plandan kolayca ayırt etmek için belgeye bölümleme uygulamayı amaçlar .
4. Karakterleri Tanıma
Bu adımda, harfleri veya rakamları tanımlamak için siyah alanlar daha fazla işlenir. Genellikle, bir OCR her seferinde bir karaktere veya metin bloğuna odaklanır. Karakterlerin tanınması, aşağıdaki iki algoritma türünden biri kullanılarak gerçekleştirilir:
- Desen tanıma. Örüntü tanıma algoritması , OCR yazılımına farklı yazı tiplerinde ve biçimlerde metin eklemeyi içerir. Değiştirilen yazılım daha sonra taranan belgedeki karakterleri karşılaştırmak ve tanımak için kullanılır.
- Özellik tespiti. Özellik algılama algoritması aracılığıyla OCR yazılımı, taranan belgedeki karakterleri tanımlamak için belirli bir harf veya sayının özelliklerini dikkate alan kurallar uygular. Özelliklerin örnekleri, karakterleri karşılaştırmak ve tanımlamak için kullanılan açılı çizgilerin, çapraz çizgilerin veya eğrilerin sayısını içerir. Bu tür metin tanıma teknikleri, çoğu derin öğrenme OCR yönteminin temelidir.
Basit OCR yazılımı, en yakın eşleşmeyi belirlemek için taranan her harfin piksellerini mevcut bir veritabanıyla karşılaştırır. Bununla birlikte, karmaşık OCR biçimleri, fiziksel özellikleri karşılık gelen harflerle karşılaştırmak ve eşleştirmek için her karakteri eğriler ve köşeler gibi bileşenlerine ayırır.
5. Doğruluğun Doğrulanması
Karakterlerin başarılı bir şekilde tanınmasından sonra, doğruluğu sağlamak için OCR yazılımının dahili sözlüklerinden yararlanılarak sonuçlar çapraz referanslandırılır. OCR doğruluğunun ölçülmesi, bir OCR tarafından gerçekleştirilen bir analizin çıktısının alınması ve orijinal versiyonun içeriğiyle karşılaştırılmasıyla yapılır.
OCR yazılımının doğruluğunu analiz etmek için iki tipik yöntem vardır:
- Karakter düzeyinde doğruluk , kaç karakterin doğru algılandığını sayar.
- Kelime düzeyinde doğruluk, kaç kelimenin doğru tanındığını sayar.
Çoğu durumda, sayfa düzeyinde (algoritma düzeyinde değil) ölçülen %98-99 doğruluk kabul edilebilir doğruluk oranıdır. Bu, yaklaşık 1.000 karakterlik bir sayfada 980-990 karakterin OCR yazılımı tarafından doğru bir şekilde tanımlanması gerektiği anlamına gelir.
En iyi OCR algoritması ve son teknoloji
En doğru OCR Algoritmaları
Vision Transformers’a (ViT) dayalı ve Haziran 2022’de piyasaya sürülen MaskOCR, en iyi performans gösteren OCR algoritmasıdır ve hem Çince hem de İngilizce metin görüntüleri için kıyaslama veri kümelerinde üstün sonuçlar elde eder. Çin BCTR veri kümesinde Optik Karakter Tanıma için önceki en iyi algoritma olan TransOCR, MaskOCR tarafından geride bırakıldı.
MaskOCR’nin küçük model versiyonu, karşılaştırılabilir model boyutlarıyla Optik Karakter Tanıma için önceki en iyi algoritmayı geride bırakıyor. Spesifik olarak, Mask OCR yöntemi, ön eğitim için yalnızca 4,2 milyon gerçek veri noktası kullanırken, 100 milyon gerçek veri ile önceden eğitilmiş olan PerSec’ten daha iyi doğruluk sağlar.
ABINet ve uzantısı ConCLR, MaskOCR’nin küçük ViT sürümüne benzer şekilde performans gösterirken, MaskOCR en yeni sonuçları %93,8’lik yeni bir doğruluk düzeyine taşıyor.


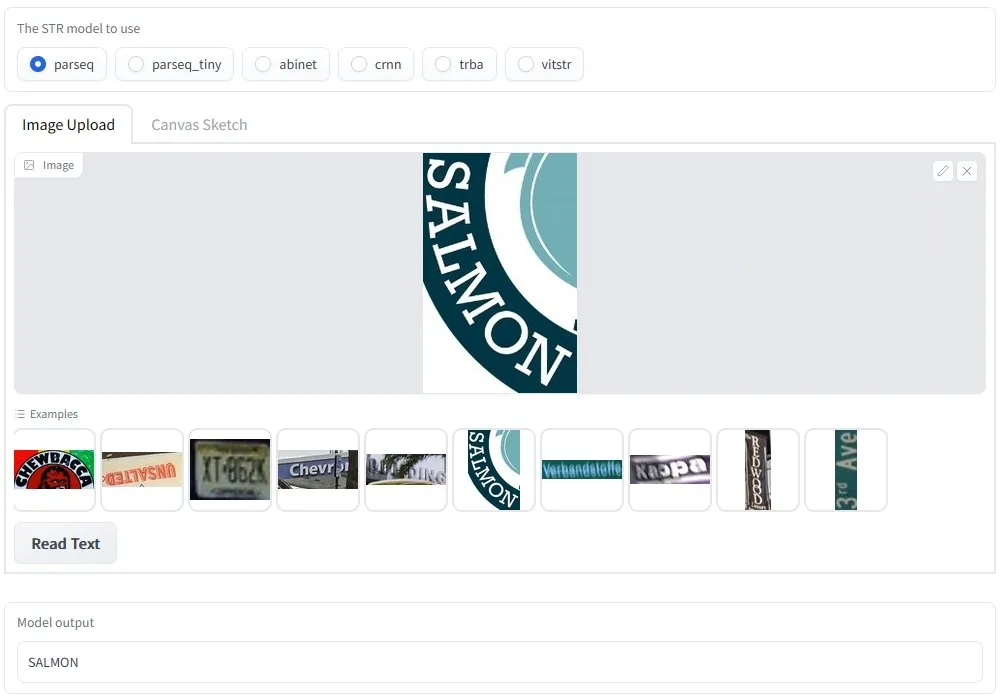
OCR Algoritmalarını Kendiniz Test Edin
Sentetik eğitim verileri ( veri artırma hakkında daha fazla bilgi) kullanılarak eğitildiğinde STR (Sahne Metni Tanıma) kıyaslamalarında (%91,9 doğruluk) yüksek performanslı sonuçlar elde eden PARSeq modelini test etmek için bu etkileşimli demoyu kullanın .
- Kullanılacak OCR modelini seçin
- Bir metin resmi yükleyin veya verilen bir örneği kullanın
- “Metni Oku”ya tıklayın
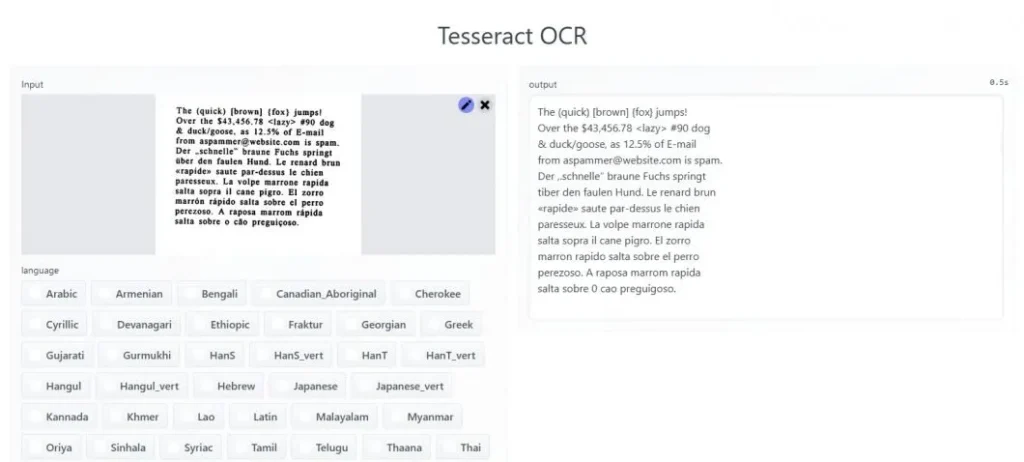
Tesseract OCR
Tesseract nedir?
Tesseract, taranan metni okuyabilen ve dijital metne dönüştürebilen bir karakter tanıma motorudur. Apache Lisansı 2.0 altında yayınlanan açık kaynaklı bir yazılımdır. Tesseract, Windows, Linux ve Mac OS X dahil olmak üzere çeşitli işletim sistemlerinde kullanılabilir.
Bu nedenle Tesseract, taranan belgeler ve dijital fotoğraflar gibi görüntülerdeki metinleri tanımak için popüler bir araçtır. Tesseract doğru ve etkilidir ve çeşitli dilleri işleyebilir.
Test için Tesseract OCR Yazılım Demosu
Tesseract ile resimlerdeki metni tanımak için metin içeren resimler girersiniz. Tesseract, JPG, PNG ve TIFF dahil olmak üzere çeşitli görüntü formatlarını okuyabilir.
Huggingface’te kolayca barındırılan modelle Tesseract’ı ücretsiz olarak kullanmanın ve test etmenin kolay bir yolu: Tesseract OCR yazılımını test edin.
Optik Karakter Tanıma Kullanım Örnekleri
Her şey dijitalleşirken ve gelişirken, çeşitli işletmeler tarafından yapay zeka tabanlı OCR çözümleri aracılığıyla iş süreçlerini kolaylaştırmak, erişilebilirliği iyileştirmek ve müşteri memnuniyetini artırmak için OCR yazılım çözümleri kullanılıyor.
Aşağıda, bugün endüstrilerdeki en iyi OCR çözümlerinden bazılarını listeliyoruz.
OCR ile Plaka Tanıma
Otomatik plaka tanıma (ANPR), araç plakalarındaki numaraları tanımlamak için OCR teknolojisini kullanır. Günümüzde, plaka tanıma, çalıntı arabaları bulmak, park ücretlerini hesaplamak, geçiş ücretlerini faturalamak veya güvenlik bölgelerine erişim kontrolü ve daha fazlası için çeşitli ticari uygulamalarda kullanılmaktadır.
Bankacılıkta Yapay Zeka Tabanlı OCR Uygulamaları
Bankacılık sektörü, güvenliği artırmaya, veri yönetimini iyileştirmeye, risk yönetimini optimize etmeye ve müşteri deneyimini geliştirmeye yardımcı olduğu için OCR tanıma uygulamalarının en büyük tüketicilerinden biri olarak kabul edilir.
OCR teknolojisini uygulamadan önce, müşteri kayıtları, çekler, banka ekstreleri ve diğerleri dahil olmak üzere çoğu bankacılık belgesi fizikseldi. Bir OCR tanıma çözümünün kullanılmasıyla, daha eski belgeleri bile veritabanlarında sayısallaştırmak ve depolamak mümkün hale gelir.
OCR teknolojisi aynı zamanda bankacılık sektöründe de tamamen devrim yaratmıştır:
- Kolay doğrulama sağlama : OCR, para yatırma çeklerinin ve bir imzanın OCR tabanlı bir uygulama kullanılarak taranarak gerçek zamanlı olarak doğrulanmasına olanak tanır. Bunun bir örneğini, çeklerin dijital olarak ibraz edilebildiği ve OCR tabanlı çek tevdi özellikleri sayesinde günler içinde işlenebildiği mobil bankacılık uygulamalarında görebiliriz.
- Güvenliği artırma : Çeklerin OCR teknolojisi aracılığıyla elektronik olarak ödenmesi, dolandırıcılığın önlenmesine ve işlemlerin giderek daha güvenli hale gelmesine yol açarak daha iyi bir kullanıcı deneyimi sağlar. OCR, sahte belgeleri tespit etmek için karakter okuyucu sayısını ve makine öğrenimi yöntemlerini kullanabilir.
Sağlık Sektöründe OCR Kullanım Örnekleri
OCR makine öğreniminin sağlık sektörü için faydalı olduğu kanıtlanmıştır. Sağlık sektöründe OCR teknolojisi, hastaların tıbbi geçmişlerine hem hastalar hem de doktorlar tarafından dijital olarak erişilmesini sağlar.
Ayrıca, röntgenleri, tedavileri, testleri, hastane kayıtları ve sigorta ödemeleri de dahil olmak üzere hasta kayıtları, kayıtları dijitalleştirmek ve kameralarla etiketleri okumak için tam biçimli OCR yöntemleri kullanılarak kolayca taranabilir, aranabilir ve saklanabilir.
Böylece, optik karakter tanıma, kayıtları güncel tutarken iş akışını kolaylaştırmaya ve hastanelerdeki manuel işi azaltmaya yardımcı olur.
Ulaşımda OCR nasıl kullanılır?
OCR teknolojisi, akıllı park etme, akıllı ücretlendirme ve ulaşım sektörlerinde devrim yarattı. İster uçuş veya otel rezervasyonu yapıyor olun, ister havaalanında veya otel odanızda check-in yapıyor veya seyahat harcamalarınızı yönetiyor olun, müşteri deneyimini geliştirmek için her temas noktasında yapay zeka tabanlı OCR çözümleri kullanılabilir.
Havaalanlarının ve mobil seyahat uygulamalarının çoğu, güvenlik ve dokümantasyon uygulamalarında otomatikleştirilmiş veri çıkarma için makine öğrenimi OCR teknolojisini kullanır. OCR araçlarının uygulamaları, uçuş veya otel rezervasyonu yaparken pasaport taramaktan kişisel verilerin saklanmasına kadar uzanır.

Optik Karakter Tanıma Avantajları
Optik Karakter Tanıma, çoğu bu makalede incelenen çok çeşitli avantajlar sunar. Bununla birlikte, AI tabanlı metin tanıma sistemlerinin en önemli faydaları, referansınız için aşağıda listelenmiştir.
- Geliştirilmiş doğruluk: Yazılım tabanlı karakter tanıma, insan hatalarını ortadan kaldırarak daha iyi doğruluk sağlar.
- Süreçleri hızlandırın: Teknoloji, yapılandırılmamış verileri aranabilir bilgilere dönüştürerek, gerekli verileri daha hızlı kullanılabilir hale getirir ve ardından iş süreçlerini hızlandırır.
- Uygun maliyetli: OCR teknolojisi çok fazla kaynak gerektirmez, bu da işleme maliyetlerini düşürür ve sonuç olarak bir işletmenin genel maliyetlerini düşürür.
- Gelişmiş müşteri memnuniyeti: Müşteriler tarafından aranabilir verilere erişilebilirlik, iyi bir deneyim sağlayarak daha iyi müşteri memnuniyeti sağlar.
- Geliştirilmiş üretkenlik: Aranabilir verilere kolay erişilebilirlik, çalışanlar için stressiz bir ortam oluşturarak ana hedeflere odaklanmalarına olanak tanıyarak bir işletmenin üretkenliğini artırır.
Sıradaki ne?
Optik karakter tanıma (OCR), taranan görüntüleri ve diğer görselleri metne dönüştürmek için kullanılır. Bu, kağıt tabanlı belgeleri düzenlenebilir ve aranabilir dijital ortamlara dönüştürür ve otomatik bir optik karakter tanıma (OCR) sisteminin geliştirilmesini sağlar.



